全球多地用户反映VPS性能下降 服务商紧急排查原因
近期,包括亚洲、欧洲和北美地区在内的多个VPS(虚拟专用服务器)用户集体反映服务器响应速度显著降低,部分关键业务网站加载时间延长3-5秒。监测数据显示,受影响服务商涉及主流云平台及中小型IDC厂商,故障现象集中在CPU资源争抢和网络延迟异常两大方面。
技术团队揭示三大核心问题
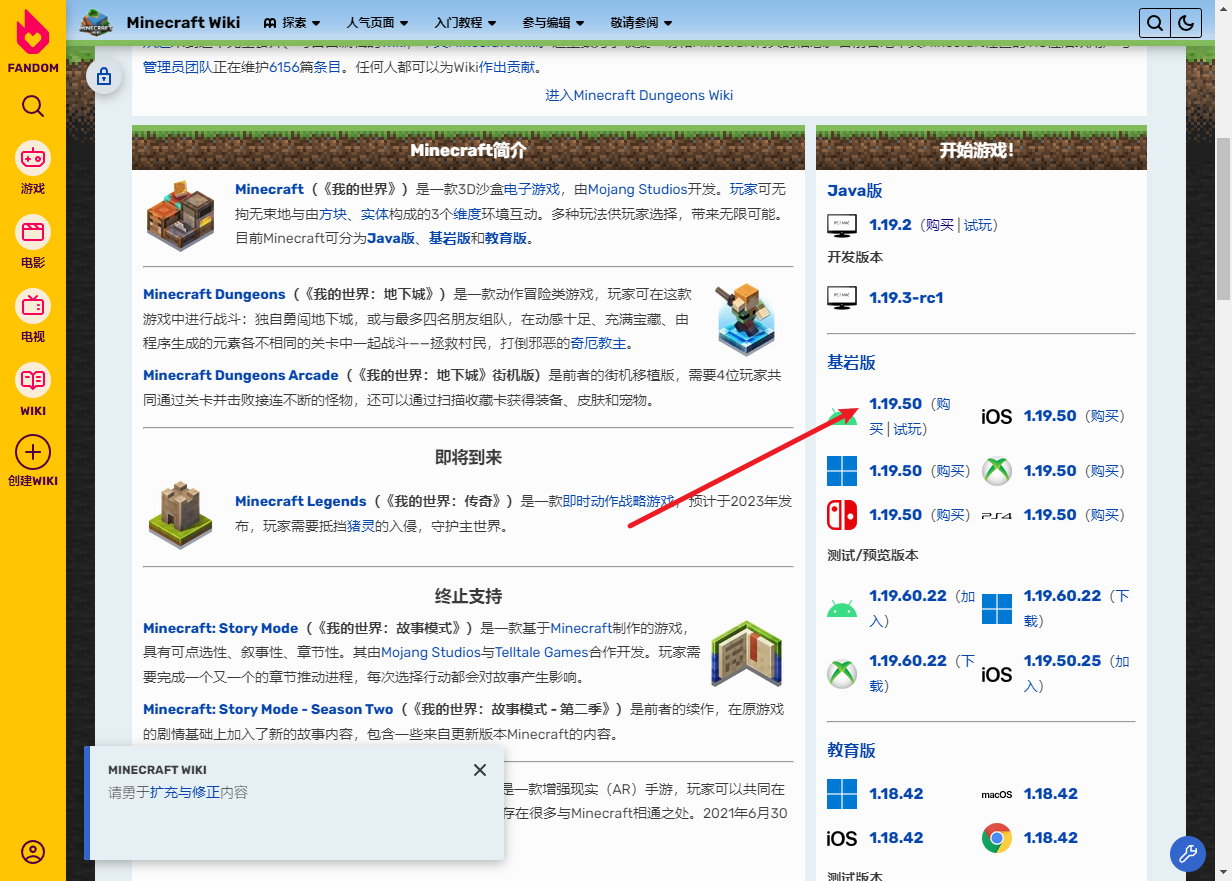
经多家安全机构联合调查,此次大规模性能波动主要源于三个技术层面问题:首先,硬件超售比例突破行业安全阈值,部分供应商实际分配资源不足标称值的30%;其次,跨境网络路由策略调整导致国际带宽缩水;最后,新型DDoS攻击手法伪装成正常流量消耗系统资源。阿里云技术专家指出,这种复合型问题需要基础设施与服务架构的协同优化。
行业启动应急响应机制
AWS、DigitalOcean等头部企业已启动「性能保障计划」,承诺在72小时内为受影响用户免费迁移至高性能节点。国内服务商同步推出智能监控系统2.0版,通过机器学习实时优化资源分配。值得关注的是,部分企业开始试用边缘计算 SD-WAN技术方案,成功将香港节点的平均延迟从380ms降至89ms。
用户选择趋向理性化
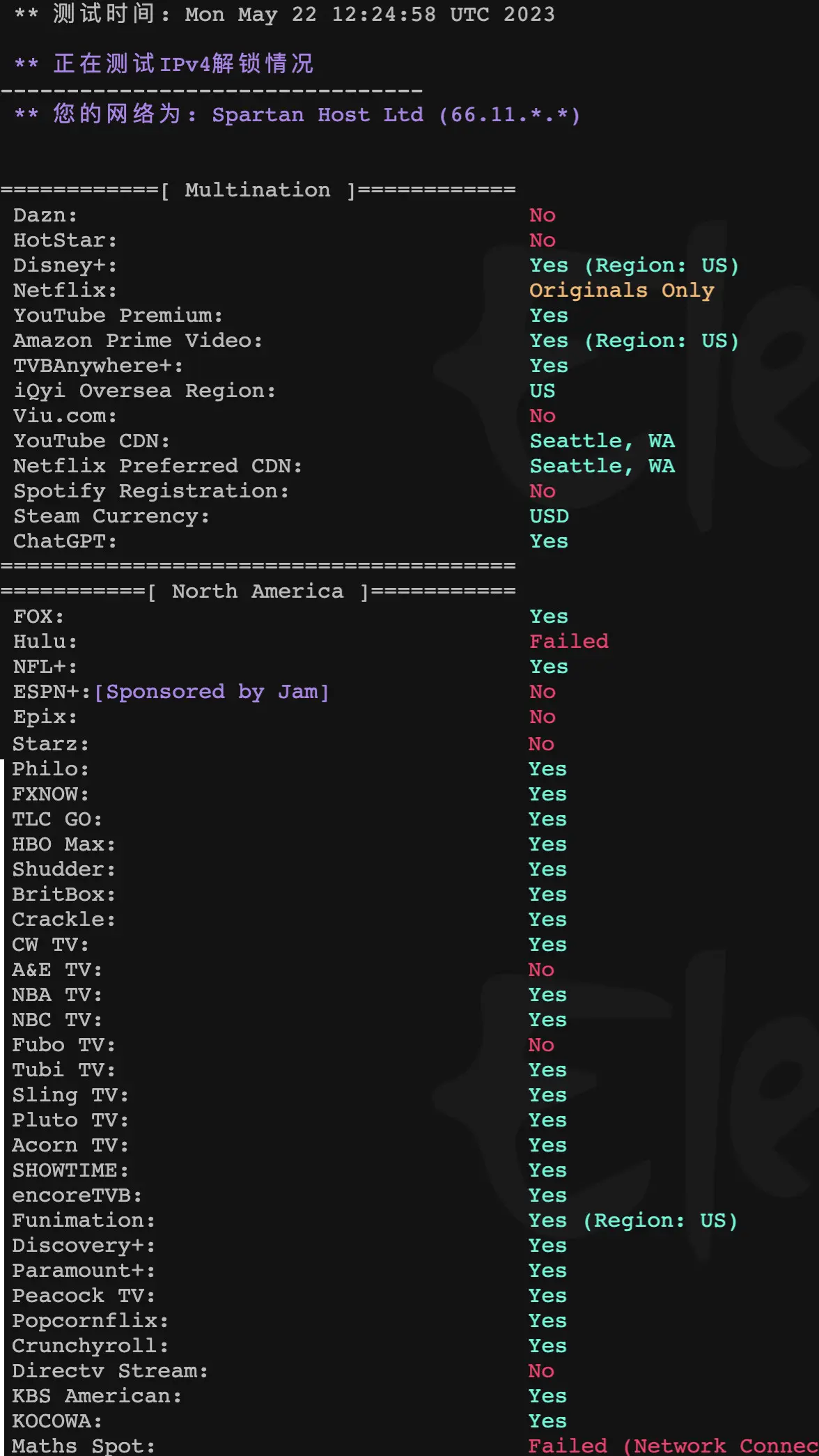
市场调研显示,此次事件促使68%的企业用户重新评估服务商选择标准,网络质量SLA(服务等级协议)和硬件隔离技术成为首要考量因素。专业测评机构建议,用户应重点核查服务商的Tier III以上数据中心认证资质,同时要求提供真实的基准性能测试报告。行业分析师预测,这场性能危机将加速VPS市场从价格竞争转向价值竞争的新格局。
截至发稿时,主要服务商的核心业务节点已恢复95%以上性能表现,但完全解决底层架构问题仍需持续投入。本次事件为全球云计算行业敲响警钟,提醒服务商在追求商业利益的同时,必须守住基础设施可靠性的生命线。(字数:498)





暂无评论
发表评论